
eZ Platform and a Graph Database?
So what is a Graph Database?
Wikipedia describes Graph Databases in a way that is instantly familiar to anyone who has modelled any kind of objects and their relationships:
In computing, a graph database is a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data.
Accompany this with the graph (pun intended) below and you've got an idea of what's going on and what it could be useful for:
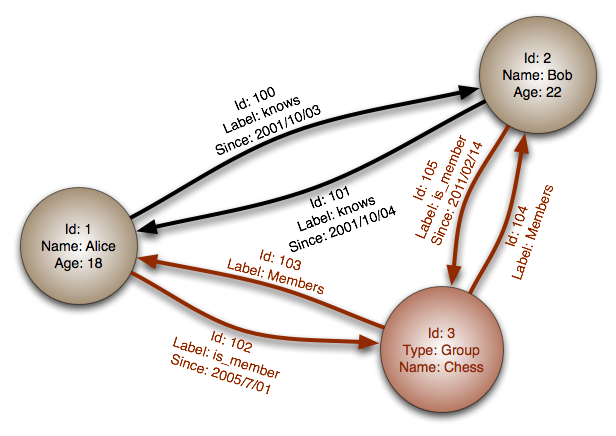
You then query these kind of data models with a query language, Neo4j for example uses the Cypher language:
MATCH (charlie:Person { name:'Charlie Sheen' })-[:ACTED_IN]-(movie:Movie)
RETURN movie
I was first introduced to Graph Databases in a practical way for web developers in the PHP User Group Finland meetup in 2014 though the Losofacebook demo application. In the session Pekkis went through the basics of Graph Databases and that showed a running application built with the Facebook tech stack.
I mostly work with content management - not bleeding edge social media services which is a great example of where Graphs rule supreme, but only if you've got vast amounts of data.
The eZ Platform Content Repository Concepts
In eZ Platform (and eZ Publish) all data (content, users, user groups, media...) is stored as the same type of objects. These objects have a tree structure with varying data fields, multiple locations, multiple translations and versioning. If you are unaware of eZ content concepts, see the Content Management Concepts in eZ Publish.
In addition the Rich Text Editor stores the content in semantical XML, not HTML. Storing the data in this way means that the system is aware of which other objects are related to it and what objects it relates to. With traditional relational database stores the relations, but they will get slow (reverse relations, sorting) when you add data and complex content models.
Querying a separate search index built with Solr solves a lot of problems with this by providing faceting and great performance. But it's still a flat index with references artificially built in.
I am by no means a domain expert in Search Technologies or Graph Databases, but it does seem feasible to map the eZ content repository to a Graph Databases such as:
- ArangoDB (with ArrangoDB PHP driver)
- OrientDB (with OrientDB PHP driver)
- Neo4j (with Neo4j PHP REST Wrapper)
Mapping the eZ content model to a Graph DB
So I didn't think much of Graph Databases after learning about them. They were cool, but I don't think I'll ever need it. I skimmed through an O'Reilly book on Graph Databases (available free at the Neo4j site as an eBook) to get a grasp of the basics.
After discussing how other WCMSes are putting efforts to apply a more semantic content model, I realised the eZ repository has a lot of data I could map to a useful Graph. It might not only be useful to Facebook, Twitter and the likes.
You could probably generate interesting data from a relatively low amount of content, nothing close to the gazillion docs Google has in it's index. The graph could be further enriched with data from an integrated eCommerce application, similar to the Sylius solution from Netgen and who knows what else. It wouldn't need to be just about eZ Platform content, similar to the indexing of other data to the eZ Solr index.
So let's see, what could we apply to a graph from the eZ Platform Repository:
- Object relations (manual and automatic via Rich Text)
- Locations (tree structure, parent-child)
- Sections (arbitrary classification of content)
- Creator and editors
- Tags and taxonomies
- Ownership and permissions
- Geotagging
That's just a few I came up with very quickly on a short flight. Languages are another obvious one, but I couldn't figure out how to best map them right off the bat. Maybe have objects and separate translations linked?
The indexing process could be complex as well, maybe a two step initial indexing would be the safest:
- Index all the object on first run
- Create all the relations on the second run
Once you would have your eZ Publish content data from, say 2004, in a Graph Database. You could start imagining a whole new sets of queries you could run against it: All users who belong to the user group "Country Editors" and have ever modified content in the private section with embedded videos? Got it. Fast.
This would give new vistas to existing data, by leveraging the relationships currently mostly hidden in the background.
A Monumental undertaking? Search Packagist!
I see that there are a lot of cases where synching to data stores will have a lot of unexpected complexities. And this is not a first priority for the team at eZ Systems working on eZ Platform, so don't expect this to be a fast thing to implement or at the top of anyone's priority list. In addition pricing of Neo4j might be an issue with for some.
However, as eZ Platform now builds on the Symfony Full Stack framework, there is a number of results in Packagist for that allow us to access Neo4j as an additional model in Symfony applications. One such example is the Neo4j OGM Bundle from Klaus Silveira:
This bundle provides a simple integration of the "Neo4j PHP Object Graph Mapper" from Louis-Philippe Huberdeau into Symfony2. The Neo4j OGM is an object management layer built on top of Josh Adell's Neo4jPHP. It allows manipulation of data inside the Neo4j graph database through the REST connectors.
As we've learned before, the Symfony 2 full stack framework can fluently use different data layers. So in this case a bundle provides a simple integration of the Neo4j PHP Object Graph Mapper into Symfony2. In theory we could build a simple indexer with it to leverage existing content repository data in Neo4j:
- Index content
- Index relationships in content
- Provide a simple Query API (for Cypher)
The first POC (Proof of Concept) of integrating eZ Platform and Neo4j should be very simple, with only one translation and only mass indexing (no synching on updates, etc.). If indexing full content is tricky - just go the easy way fetch content from MySQL once you get the relevant content IDs from the results. It'll be slow, but queries work.
Once you would have this data, you could realise you're sitting on a gold mine (or oil field, if you're Norwegian) of data you never practical had access to. Incidentally the creators of Neo4j started out in Content Management. That is no accident.